Horror-Dating-Sim auf itchio: Melissa
tl;dr: unausgegorenes Hirnen über Gemeinsamkeiten und Unterschiede zwischen Dating-Sims, Porngames, Indiespielen zum Thema bei schmalen Stichproben. Vermutung, dass die Jugend nicht verdirbt, Abschlussabschweifung zu Krautchan/b/ und, hihi, KI und Botspam auf sozialen Netzwerken. Folgend wahrscheinlich NSFW.
Ich weiß nicht mehr, was mich vor einiger Zeit zu itch.io schubste, jedenfalls stieß ich dort auf „Date Time“ von CatTrigger, und nachdem man da Melissa direkt im Browser spielen konnte, spielte ich ein wenig rein und fand die Geschichte sehr charmant.
Weiter treibe ich mich ja noch gelegentlich auf fragwürdigen Webseiten rum, die einen bei Nutzung denn Bildschirm mit Popups zukleistern für Camsex, Gambling, Standardporn und Hentaikram, letzterer in verschiedenen Ausprägungen und teils zumindest rudimentär „beziehungssimulierend“. Das Genre hatte ich immer eher als etwas pubertäre Comicwichsvorlage abgehakt und nicht näher angesehen.
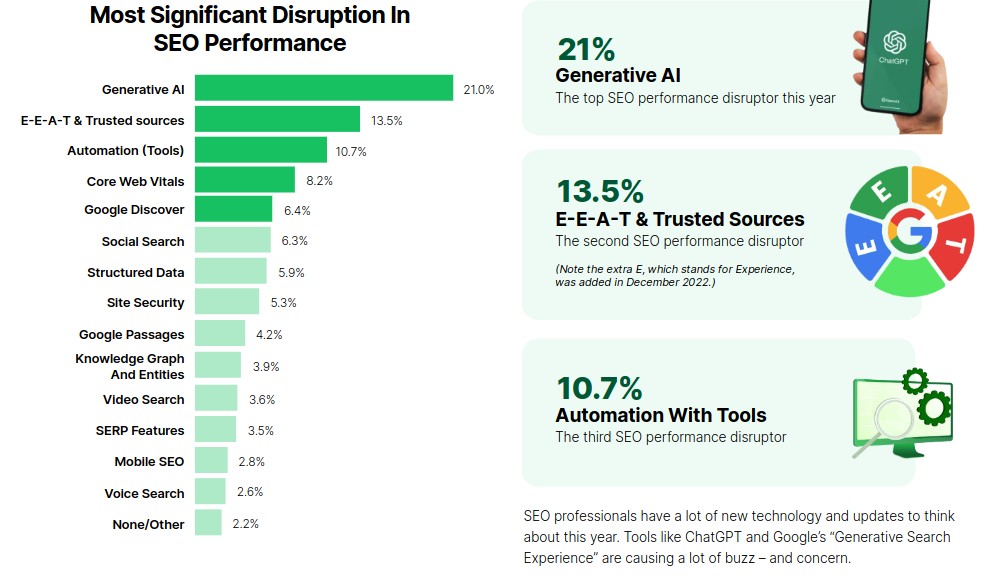
Nun stöberte ich auf itch.io ein bisschen weiter bei den Dating-Sims rum (over 5.000!) und war etwas getriggert.

OVER 5.000! Datingsims auf itch.io
Hier bauen Leute in nennenswerter Zahl Dating-Spiele im engeren bis weiteren Sinn, in unterschiedlichsten Ausprägungen, Nischen und Fandoms, pflegen dabei diverseste Themes (Logisch: Manga, LGBTQI, aber eben auch Fantasysettings, Furrykram, Vampirstories, Mittelalter, you name it. „Space Gays“, fick ja, we’ve came a long way).
Nun muss man dazusagen, dass meine bisherigen Begegnungen mit dem Genre ein bisschen Gronkh-Trash-Game Lets Plays waren und das Gesehene bestenfalls cringy war und schlimmstenfalls etwas entschärfte PUA-Scheiße für Arschlöcher.

Es ist so schlimm, wie es aussieht

Das hier ist indessen schlimmer wie es aussieht
Eine andere Strömung kommt aus Japan (obviously), aber wie man sieht, hat sie sich verbreitet. (Das oben erwähnte Date Time: „Melissa“ ist interessanterweise ein 8Bit-Horror-Derivat exakt dieses Genres.)

Melissa kann viel mit 4K RAM.
itch.io hatte ich halt ein wenig quergescrollt, aber dabei kriegte ich ein ziemliches Deja-Vu zu meinem Augenöffner in Sachen Fan Fiction, Pornografie und weibliche Zielgruppe: da schien eine größere Community mit eher schwacher cis-männlicher Prägung am Bauen und Spielen von Sims/Visual Novels mit unterschiedlich expliziten Inhalten zu sein. Erster Reflex: schön! Zweiter Reflex: was ist da eigentlich das Mainstream-Äquivalent?
Das brachte mich dazu, die bislang meist schnell geschlossenen Popups auf erwähnten fragwürdigen Seiten nicht nur mal anzusehen, sondern auch explizit anzuklicken. Tja, nun.

PFAD DES SEXGOTTES!!!11

Wir wissen, wie das enden wird.
Ich sag mal so, was man hier sieht, geht genauso weiter wie man vermutet. Und nun kann man versuchen, sich das ein wenig schönzureden – so wird recht klar angesagt, dass die Mädels wissen, was sie wollen, dass man rücksichtsvoll, einfühlsam, whatever sein muss, damit sie einen mögen usw., yaddayadda, aber klar bewegen wir uns in eher niedrigeren Sphären der Reduktion von Gegenübern zu wunscherfüllenden Fantasieobjekten.
Wer bzw. wieviele sind da unterwegs? nun, ein paar Leute durchaus. Weiterlesen